

Large language models (LLMs) have become indispensable tools across various applications, from customer service to content creation. However, recent research has uncovered a counterintuitive phenomenon:
Increasing the length of prompts can degrade the performance of these models.
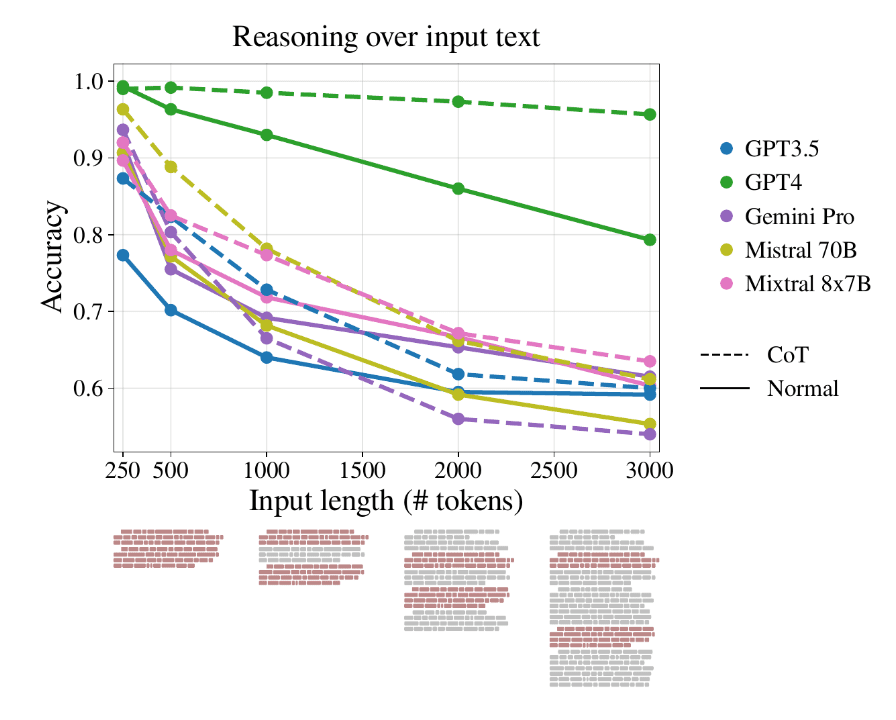
The Inverse Relationship Between Prompt Length and LLM Accuracy
Studies have revealed a notable decline in LLMs’ reasoning performance as input lengths increase. This degradation occurs well before reaching the models’ technical maximum input length, challenging the assumption that more context always leads to better performance. Researchers have found that longer prompts often introduce irrelevant or redundant information, distracting the model and producing suboptimal outputs.
The research, detailed in the paper, “Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models,” highlights that LLMs quickly degrade in their reasoning capabilities even with input lengths of 3,000 tokens, much shorter than their technical maximum.
The study used a novel quality assurance (QA) reasoning framework to isolate the effect of input length, revealing that traditional perplexity metrics do not correlate with performance in long input reasoning tasks. This finding underscores the need for more nuanced evaluation methods to fully understand LLM performance across varying input lengths.
Why Longer Prompts Fail to Guarantee Better LLM Performance
Although it may seem intuitive that providing more context would enhance an LLM’s ability to generate informed responses, the reality is quite different.
Longer prompts can overwhelm the model’s processing capabilities, leading to a decline in performance. This is particularly evident in tasks that require complex reasoning, where the model’s ability to locate and prioritize relevant information diminishes as the input length grows.
Moreover, traditional metrics do not correlate well with performance on long input reasoning tasks. This discrepancy highlights the need for more nuanced evaluation methods that consider the specific challenges posed by extended prompts. As a result, simply adding more tokens or steps to a prompt is not an effective solution for improving LLM performance.
The Perils of Prompt Overloading: How Excessive Tokens Undermine LLM Accuracy
When confronted with overwhelming information, LLMs may struggle to identify and prioritize the most relevant details, leading to unfocused, inconsistent, or even contradictory outputs to the intended task.
This phenomenon is exacerbated by the model’s tendency to exhibit biases toward less relevant information as input length increases. Studies have shown that LLMs often fail to follow extended instructions and may provide incomplete or incorrect responses. These findings uncover the importance of avoiding prompt overloading and focusing on concise, relevant inputs.
Finding the Optimal Prompt Length for Peak LLM Performance
Identifying the optimal prompt length is essential for maximizing LLM performance. While excessively long prompts can hinder accuracy, overly concise prompts may also fail to provide sufficient context for the model to generate accurate outputs. Researchers have identified optimal prompt lengths that vary depending on the task, dataset, and LLM architecture.
These guidelines help users balance between providing enough context and avoiding information overload. It enhances accuracy and improves computational efficiency, reducing resource strain and enabling faster response times.
Crafting concise and focused prompts is key to unlocking LLMs’ true potential. Instilling the essential information and eliminating unnecessary details will allow users to guide LLMs in concentrating on the most relevant aspects of the task. Concise prompts also help mitigate the risk of hallucinations, where the model generates outputs not grounded in the provided context. By focusing on the most relevant information, users can ensure that LLMs produce more accurate and reliable responses, enhancing the overall quality of interactions.
Crafting Effective Prompts for Accurate LLM Outputs
Adopting best practices in prompt engineering is essential to harness the full power of LLMs. These include clearly defining the task and desired output format, providing relevant context and background information, prioritizing conciseness, and avoiding redundancy.
Iteratively refining prompts based on LLM performance can also help optimize accuracy and efficiency. This is particularly important in applications where precision and reliability are critical, such as healthcare, finance, and legal services.
Although prompt length is a crucial factor in LLM performance, it is not the sole consideration. Recent studies have highlighted the importance of context and relevance in prompt design. An effective prompt design is about more than just length. It is about providing the right context and ensuring every word serves a purpose.
How Aporia’s Guardrails Safeguard AI Interactions
As the field of natural language processing continues to evolve, a deeper understanding of prompt design principles will be crucial in harnessing the full capabilities of these powerful models. However, one thing is certain: guardrails can do wonders in mitigating the risks associated with LLM hallucinations.
Artificial intelligence (AI) engines like Aporia provide a protective layer between the LLM and the user interface, continuously monitoring and mitigating potential issues like hallucinations, prompt injection poisoning, and SQL attacks.
Designed for AI, including multimodal applications that integrate text, audio, video, and images, Aporia’s solution becomes increasingly crucial as LLMs handle more diverse data inputs, heightening the risk of inaccurate or ungrounded responses.
One key feature of Aporia’s guardrails is their ability to detect and mitigate up to 94% of hallucinations in real-time before they reach users. This ensures that LLM outputs remain accurate and grounded in the provided context.
Users can also define custom security rules and guidelines to tailor the guardrails to their needs, aligning LLM interactions with company policies, ethical standards, and regulatory requirements. Operating at sub-second latency and with streaming support, these guardrails enable real-time monitoring and mitigation without introducing delays in the user experience.
Aporia’s guardrails are designed to prevent malicious uses of LLM applications as well, such as prompt injections or prompt leakage, which risks exposing sensitive information.
When integrated into LLMs, organizations can enhance their AI systems’ safety, reliability, and accountability, building trust in AI-powered interactions across various industries and use cases, even when dealing with longer prompts or multimodal inputs.